Model view controller is nothing but a design pattern used to achieve customizability in our application. Change is the only thing in the world, which will never change. All the products that we develop to our clients will undergo many changes. To accommodate these changes we should concentrate more on our design. Directly jumping in to the code may give quick solutions to our problem but they will not solve our future problems of customizability and re-usability. So friends in this article we will discuss about MVC a most popular design pattern, which helps us to overcome most of our problems. Initially we may feel that this design pattern will need more time before starting the development. Yes it is true, but the time, which we spend on design, will give some fruitful benefits.

Good Layering Approach
MVC follows the most common approach of Layering. Layering is nothing but a logical split up of our code in to functions in different classes. This approach is well known and most accepted approach. The main advantage in this approach is re-usability of code. Good example of layering approach is UI, Business Logic, and Data Access layer. Now we need to think how we can extend this approach to give us another great advantage customizability. The answer to this is using Inheritance. Inheritance is one of the powerful concepts in oops. .Net supports this in a nice way.
Visual Inheritance in .Net
Before getting in to Visual Inheritance, we will discuss the basic difference between Inheritance and Interfaces.

Inheritance -- what it is?
Interfaces -- How it should be? (It’s a contract)
Both these answers target the classes, which we are designing in our application. Many of us know this definition but we will not use this extensively in our application including me. Unless we work in a design, which uses these concepts to a great extent, we will not agree this. Many of the Microsoft products use this to a great extent. For example how Commerce Server pipeline components achieves the customizability. Commerce Server allows us to create our own component in com and allow us to add it as one of a stage in the pipeline. How they achieve this, only through interfaces. We need to create a com component and the com component should implement a interface. All the objects in our .Net Framework class libraries are inherited from System.Object. This tells us the importance of Inheritance.
Jumping into Visual Inheritance
Let's try out one of .Net most interesting feature, Visual Inheritance. What exactly is it? Now we do know what is inheritance right? No I don't mean the money that you get from your parents/grand parents, I'm talking about class and interface inheritance, which saves you the headache of re-typing code and provides the luxury of code reusability. Now wouldn't it be nice if the same feature that applies to classes and their methods could also be applied to the GUI forms that we create, I mean create a base form with our corporate logo so that it appears on all of the firm's screens? Well such a feature now exists! Yes, you've guessed it, its Visual Inheritance! Visual Inheritance alone will not solve our problem of extensibility. This will help us to start digging our mind for solution. Cool guys now we will directly jump in to our problem with a good example.

Problem Statement
I have an employee master screen, which takes Name and Age as inputs and save the same in our database.

Lets assume this is my basic functionality in my product, which serves most of my customer’s requirement. Now let us assume one of my new client asks for a change in this form. He needs an additional field in this form, which takes the employee’s address and stores the same in the database. How will we achieve this? Normally we will create a new screen which will also has a textbox to get the address input, in the same time we will also add another column in the employee master table and supply the new binaries and modified table and stored procedure scripts to the client. Do you think this is the right approach? If you ask me this is one of the crude way to satisfy an customer. Requirement like this will be very easy to re-write the entire code. But think if a customer asks a change in Payroll Calculation logic. Re-writing code for some specific customers will not helps us in long run. This will end up in maintaining separate – separate Visual source safe for each and every client. These types of solutions are very difficult to handle and after some time we will feel that we have a messy code.
The right way to solve this problem is by having a good design pattern in place and make sure that the entire team clearly understands the design and implements the same in their code. We can solve this by doing a layered approach using MVC and Visual Inheritance.
Solution to our problem
1. Don’t alter the table add another table which stores the additional columns like address and the junction/extended table should have a foreign key relationship with our main employee table.
2. Create a new Inherited form, which inherits from our main employee master screen. To use Visual Inheritance we need to change the Access Modifiers to Protected from Friend. By default VS .Net puts the access modifier as friend.
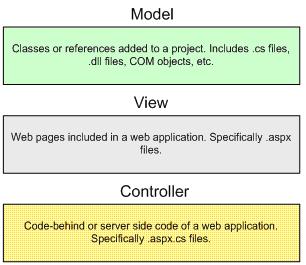
View Layer

Our View /UI layer should only have UI related validations in it. We should not have any Business Logic in to it. This gives us the flexibility to change the UI at any time and we can also have different UI for different customers. We can even have web based UI for some of the clients.
Controller /Director
Controller is the layer, which responds to the events in the UI. For example Save button click on my employee master screen. This layer should act as an intermediate between our View and Model. Initially we may think that this layer is not necessary. I am also not convinced with this layer. But still we need to think. May be after some days we will get answer for this. This layer will act as just event redirector.
Model
This layer has all our business logic. This is the most important layer. This layer will have our core functionality. This layer should be designed in such a way that out core and complex logic should be designed as functions and these function should be marked as overridable so that the inheriting classes can re-use the logic or override the logic. We should not make all the functions in the layer as overridable this may raise some security threats.
Database Operations
All the database operations should be done in the Model base class. All the inheriting classes should call this method to do database updates. The design can be like this. In my EmpModel base class I will have a protected array list which will store all the objects which needs to get updated. All the classes which inherits this class should add there objects to this array list and they should call the base class Update method. This helps us to do all the db operations in a single transaction.
For example in our example, we should create an EmployeeBase class, which will have properties for name and age. Our EmpModelBase should have a new instantiated EmployeeBase object and our view should fill the object properties. Finally the view will call the controller’s Save method and the controller should call the Model save method, there we will add the Employee object to the array list and the function should call the mybase.Update method. This method should loop through the array list and it should fire corresponding db update statements. This is just an example. We need to enhance this depending upon our requirement.
Conclusion
1. Layering Approach helps us a lot and we need to enhance it to get full customizability.
2. We need to enhance this with all our design knowledge.
3. No IDE enforces these patterns, it is up to us to do clean and disciplined way of coding.
4. Once we are used to these approaches / patterns then we are addicted to it.
 In Entity Framework 3.5 (.NET 3.5 SP1), there are more than a few restrictions that were imposed on entity classes. Entity classes in EF needed to either be sub classes of EntityObject, or had to implement a set of interfaces we collectively refer to as IPOCO – i.e. IEntityWithKey, IEntityWithChangeTracker and IEntityWithRelationships. These restrictions made it difficult if not downright impossible to build EF friendly domain classes that were truly independent of persistence concerns. It also meant that the testability of the domain classes was severely compromised.
In Entity Framework 3.5 (.NET 3.5 SP1), there are more than a few restrictions that were imposed on entity classes. Entity classes in EF needed to either be sub classes of EntityObject, or had to implement a set of interfaces we collectively refer to as IPOCO – i.e. IEntityWithKey, IEntityWithChangeTracker and IEntityWithRelationships. These restrictions made it difficult if not downright impossible to build EF friendly domain classes that were truly independent of persistence concerns. It also meant that the testability of the domain classes was severely compromised.All of this changes dramatically with the next release of Entity Framework: 4.0 (.NET Framework 4.0). Entity Framework 4.0 introduces support for Plain Old CLR Objects, or POCO types that do not need to comply with any of the following restrictions:
Inheriting from a base class that is required for persistence concerns
Implementing an interface that is required for persistence concerns
The need for metadata or mapping attributes on type members
For instance, in Entity Framework 4.0, you can have entities that are coded as shown:
public class Customer
{
public string CustomerID { get; set; }
public string ContactName { get; set; }
public string City { get; set; }
public List
}
public class Order
{
public int OrderID { get; set; }
public Customer Customer { get; set; }
public DateTime OrderDate { get; set; }
}You can then use the Entity Framework to query and materialize instances of these types out of the database, get all the other services offered by Entity Framework for change tracking, updating, etc. No more IPOCO, no more EntityObject - just pure POCO.
There’s quite a bit to discuss here, including:
Overall POCO experience in Entity Framework 4.0
Change Tracking in POCO
Relationship Fix-up
Complex Types
Deferred (Lazy) Loading and Explicit Loading
Best Practices
In this post, I will focus primarily on the overall experience so that you can get started with POCO in Entity Framework 4.0 right away. I’d like to use a simple example that we can walk through so you can see what it feels like to use POCO in Entity Framework 4.0. I will use the Northwind database, and we’ll continue to build on this example in subsequent posts.
Step 1 – Create the Model, turn off default Code Generation
While POCO allows you to write your own entity classes in a persistence ignorant fashion, there is still the need for you to “plug in” persistence and EF metadata so that your POCO entities can be materialized from the database and persisted back to the database. In order to do this, you will still need to either create an Entity Data Model using the Entity Framework Designer or provide the CSDL, SSDL and MSL metadata files exactly as you have done with Entity Framework 3.5. So first I’ll generate an EDMX using the ADO.NET Entity Data Model Wizard.
 Create a class library project for defining your POCO types. I named mine NorthwindModel. This project will be persistence ignorant and will not have a dependency on the Entity Framework.
Create a class library project for defining your POCO types. I named mine NorthwindModel. This project will be persistence ignorant and will not have a dependency on the Entity Framework. Create a class library project that will contain your persistence aware code. I named mine NorthwindData. This project will have a dependency on Entity Framework (System.Data.Entity) in addition to a dependency on the NorthwindModel project.
Add New Item to the NorthwindData project and add an ADO.NET Entity Data Model called Northwind.edmx (doing this will automatically add the dependency to the Entity Framework).
Go through “Generate from Database” and build a model for the Northwind database.
For now, select Categories and Products as the only two tables you are interested in adding to your Entity Data model.
Now that I have my Entity Data model to work with, there is one final step before I start to write code : turn off code generation. After all you are interested in POCO – so remove the Custom Tool that is responsible for generating EntityObject based code for Northwind.edmx. This will turn off code generation for your model.
 We are now ready to write our POCO entities.
We are now ready to write our POCO entities.Step 2 – Code up your POCO entities
I am going to write simple POCO entities for Category and Product. These will be added to the NorthwindModel project. Note that what I show here shouldn’t be taken as best practice and the intention here is to demonstrate the simplest case that works out of the box. We will extend and customize this to our needs as we go forward and build on top of this using Repository and Unit of Work patterns later on.
Here’s sample code for our Category entity:
public class Category
{
public int CategoryID { get; set; }
public string CategoryName { get; set; }
public string Description { get; set; }
public byte[] Picture { get; set; }
public List
}Note that I have defined properties for scalar properties as well as navigation properties in my model. The Navigation Property in our model translates to a List
NEW .NET FRAMEWORK- ENTITY FRAMEWORK- A primary goal of the upcoming version of ADO.NET is to raise the level of abstraction for data programming, thus helping to eliminate the impedance mismatch between data models and between languages that application developers would otherwise have to deal with. Two innovations that make this move possible are Language-Integrated Query and the ADO.NET Entity Framework. The Entity Framework exists as a new part of the ADO.NET family of technologies. ADO.NET will LINQ-enable many data access components: LINQ to SQL, LINQ to DataSet and LINQ to Entities.
Every business application has, explicitly or implicitly, a conceptual data model that describes the various elements of the problem domain, as well as each element's structure, the relationships between each element, their constraints, and so on.
Since currently most applications are written on top of relational databases, sooner or later they'll have to deal with the data represented in a relational form. Even if there was a higher-level conceptual model used during the design, that model is typically not directly "executable", so it needs to be translated into a relational form and applied to a logical database schema and to the application code.
While the relational model has been extremely effective in the last few decades, it's a model that targets a level of abstraction that is often not appropriate for modeling most business applications created using modern development environments.
Let's use an example to illustrate this point. Here is a fragment of a variation of the AdventureWorks sample database that's included in Microsoft SQL Server 2005:
 If we were building a human-resources application on top of this database and at some point wanted to find all of the full-time employees that were hired during 2006 and list their names and titles, we'd have to write the following SQL query:
If we were building a human-resources application on top of this database and at some point wanted to find all of the full-time employees that were hired during 2006 and list their names and titles, we'd have to write the following SQL query:SELECT c.FirstName, e.Title
FROM Employee e
INNER JOIN Contact c ON e.EmployeeID = c.ContactID
WHERE e.SalariedFlag = 1 AND e.HireDate >= '2006-01-01'
This query is more complicated than it needs to be for a number of reasons:
While this particular application only deals with "employees", it still has to deal with the fact that the logical database schema is normalized so the contact information of employees—e.g. their names—is in a separate table. While this does not concern the application, developers would still need to include this knowledge in all queries in the application that deal with employees. In general, applications can't choose the logical database schema (for example, departmental applications that expose data from the company's core system database), and the knowledge of how to map the logical schema to the "appropriate" view of the data that the application requires is implicitly expressed through queries throughout the code.
This example application only deals with full-time employees, so ideally one should not see any other kind of employees. However, since this is a shared database, all employees are in the Employee table, and they are classified using a "SalariedFlag" column; this, again, means that every query issued by this application will embed the knowledge of how to tell apart one type of employee from the other. Ideally, if the application deals with a subset of the data, the system should only present that subset of the data, and the developers should be able to declaratively indicate which is he appropriate subset.
The problems highlighted above are related to the fact that the logical database schema is not always the right view of the data for a given application. Note that in this particular case a more appropriate view could be created by using the same concepts used by the existing schema (that is, tables and columns as exist in the relational model). There are other issues that show up when building data-centric applications that are not easily modeled using the constructs provided by the relational model alone.
Let's say that another application, this time the sales system, is also built on top of the same database. Using the same logical schema we used in the previous example, we would have to use the following query to obtain all of the sales persons that have sales orders for more than $200,000:
SELECT SalesPersonID, FirstName, LastName, HireDate
FROM SalesPerson sp
INNER JOIN Employee e ON sp.SalesPersonID = e.EmployeeID
INNER JOIN Contact c ON e.EmployeeID = c.ContactID
INNER JOIN SalesOrder o ON sp.SalesPersonID = o.SalesPersonID
WHERE e.SalariedFlag = 1 AND o.TotalDue > 200000
Again, the query is quite complicated compared to the relatively simple question that we're asking at the conceptual level. The reasons for this complexity include:
Again, the logical database schema is too fragmented, and it introduces complexity that the application doesn't need. In this example, the application is probably only interested in "sales persons" and "sales orders"; the fact that the sales persons' information is spread across 3 tables is uninteresting, but yet is knowledge that the application code has to have.
Conceptually, we know that a sales person is associated to zero or more sales orders; however, queries need to be formulated in a way that can't leverage that knowledge; instead, this query has to do an explicit join to walk through this association.
In addition to the issues pointed out above, both queries present another interesting problem: they return information about employees and sales persons respectively. However, you cannot ask the system for an "employee" or a "sales person". The system does not have knowledge of what that means. All the values returned from queries are simply projections that copy some of the values in the table rows to the result-set, losing any relationship to the source of the data. This means that there is no common understanding throughout the application code about the core application concepts such as employee, or can it adequately enforce constraints associated with that concept. Furthermore, since the results are simply projections, the source information that describes where the data came from is lost, requiring developers to explicitly tell the system how inserts, updates and deletes should be done by using specific SQL statements.
The issues we just discussed fall into two main classes:
Those related to the fact that the logical (relational) model and related infrastructure cannot leverage the conceptual domain knowledge of the application data model, hence it is not able to understand business entities, their relationships among each other, or their constraints.
Those related to the practical problem that databases have logical schemas that typically do not match the application needs; those schemas often cannot be adapted because they are shared across many applications or due to non-functional requirements such as operations, data ownership, performance or security.
The issues described above are very common across most data-centric enterprise applications. In order to address these issues ADO.NET introduces the Entity Framework, which consists of a data model and a set of design-time and run-time services that allow developers to describe the application data and interact with it at a "conceptual" level of abstraction that is appropriate for business applications, and that helps isolate the application from the underlying logical database schemas.
Modeling Data at the Conceptual Level of Abstraction: The Entity Data Model
In order to address the first issue identified in the previous section what we need is a way of describing the data structure (the schema) that uses higher-level constructs.
The Entity Data Model—or EDM for short—is an Entity-Relationship data model. The key concepts introduced by the EDM are:
Entity: entities are instances of Entity Types (e.g. Employee, SalesOrder), which are richly structured records with a key. Entities are grouped in Entity-Sets.
Relationship: relationships associate entities, and are instances of Relationship Types (e.g. SalesOrder posted-by SalesPerson). Relationships are grouped in Relationship-Sets.
The introduction of an explicit concept of Entity and Relationship allows developers to be much more explicit when describing schemas. In addition to these core concepts, the EDM supports various constructs that further extend its expressivity. For example:
Inheritance: entity types can be defined so they inherit from other types (e.g. Employee could inherit from Contact). This kind of inheritance is strictly structural, meaning that there is no "behavior" inherited as it happens in object-oriented programming languages. What's in inherited is the structure of the base entity type; in addition to inheriting its structure, a instances of the derived entity type satisfy the "is a" relationship when tested against the base entity type.
Complex types: in addition to the usual scalar types supported by most databases, the EDM supports the definition of complex types and their use as members of entity types. For example, you could define an Address complex type that has StreetAddress, City and State properties and then add a property of type Address to the Contact entity type.
With all of these new tools, we can re-define the logical schema that we used in the previous section using a conceptual model:

 LINQ to Entities: Language-Integrated Query
LINQ to Entities: Language-Integrated QueryDespite the great advancements in integration of databases and development environments, there is still an impedance mismatch between the two that's not easily solved by just enhancing the libraries and APIs used for data programming. While the Entity Framework minimizes the impedance mismatch between logical rows and objects almost entirely, the integration of the Entity Framework with extensions to existing programming languages to naturally express queries within the language itself helps to eliminate it completely.
More specifically, most business application developers today have to deal with at least two programming languages: the language that's used to model the business logic and the presentation layer—which is typically a high-level object-oriented language such as C# or Visual Basic- and the language that's used to interact with the database—which is typically some SQL dialect.
Not only does this mean that developers have to master several languages to be effective at application development, but this also introduces seams throughout the application code whenever there are jumps between the two environments. For example, in most cases applications execute queries against databases by using a data-access API such as ADO.NET and specifying the query in quotes inside the program; since the query is just a string literal to the compiler, it's not checked for appropriate syntax or validated to make sure that it references existing elements such as tables and column names.
Addressing this issue is one of the key themes of the next round of the Microsoft C# and Visual Basic programming languages.
Language-Integrated Query
The next generation of the C# and Visual Basic programming languages contain a number of innovations around making it easier to manipulate data in application code. The LINQ project consists of a set of extensions to these languages and supporting libraries that allow users to formulate queries within the programming language itself, without having to resort to use another language that's embedded as string literals in the user program and cannot be understood or verified during compilation.
Queries formulated using LINQ can run against various data sources such as in-memory data structures, XML documents and through ADO.NET against databases, entity models and DataSets. While some of these use different implementations under the covers, all of them expose the same syntax and language constructs.
The actual syntax details for queries are specific to each programming language, and they remain the same across LINQ data sources. For example, here is a Visual Basic query that works against a regular in-memory array:
Dim numbers() As Integer = {5, 7, 1, 4, 9, 3, 2, 6, 8}
Dim smallnumbers = From n In numbers _
Where n <= 5 _
Select n _
Order By n
For Each Dim n In smallnumbers
Console.WriteLine(n)
Next
Here is the C# version of the same query:
int[] numbers = new int[] {5, 7, 1, 4, 9, 3, 2, 6, 8};
var smallnumbers = from n in numbers
where n <= 5
orderby n
select n;
foreach(var n in smallnumbers) {
Console.WriteLine(n);
}
Queries against data sources such as entity models and DataSets look the same syntactically, as can be seen in the sections below.
For more background and further details on the LINQ project see [LINQ] in the references section.
LINQ and the ADO.NET Entity Framework
As we discussed in the section on ADO.NET Entity Framework Object Services, the upcoming version of ADO.NET includes a layer that can expose database data as regular .NET objects. Furthermore, ADO.NET tools will generate .NET classes that represent the EDM schema in the .NET environment. This makes the object layer an ideal target for LINQ support, allowing developers to formulate queries against a database right from the programming language used to build the business logic. This capability is known as LINQ to Entities.
For example, earlier in the document we discussed this code fragment that would query for objects in a database:
using(AdventureWorksDB aw = new
AdventureWorksDB(Settings.Default.AdventureWorks)) {
Query
"SELECT VALUE sp " +
"FROM AdventureWorks.AdventureWorksDB.SalesPeople AS sp " +
"WHERE sp.HireDate > @date",
new QueryParameter("@date", hireDate));
foreach(SalesPerson p in newSalesPeople) {
Console.WriteLine("{0}\t{1}", p.FirstName, p.LastName);
}
}
By leveraging the types that were automatically generated by the code-gen tool, plus the LINQ support in ADO.NET, we can re-write the this as:
using(AdventureWorksDB aw = new
AdventureWorksDB(Settings.Default.AdventureWorks)) {
var newSalesPeople = from p in aw.SalesPeople
where p.HireDate > hireDate
select p;
foreach(SalesPerson p in newSalesPeople) {
Console.WriteLine("{0}\t{1}", p.FirstName, p.LastName);
}
}
Or, in Visual Basic syntax:
Using aw As New AdventureWorksDB(Settings.Default.AdventureWorks)
Dim newSalesPeople = From p In aw.SalesPeople _
Where p.HireDate > hireDate _
Select p
For Each p As SalesPerson In newSalesPeople
Console.WriteLine("{0} {1}", p.FirstName, p.LastName)
Next
End Using
This query written using LINQ will be processed by the compiler, which means that you'll get compile-time validation as the rest of the application code would. Syntax errors as well as errors in member names and data types will be cached by the compiler and reported at compile time instead of the usual run-time errors that are commonplace during development using SQL and a host programming language.
The results of these queries are still objects that represent ADO.NET entities, so you can manipulate and update them using the same means that are available when using Entity SQL for query formulation.
While this example is just showing a very simple query, LINQ queries can be very expressive and can include sorting, grouping, joins, projection, etc. Queries can produce "flat" results or manufacture complex shapes for the result by using regular C#/Visual Basic expressions to produce each row.
No comments:
Post a Comment